
Modern businesses rely heavily on online applications, websites, cloud platforms, and digital services. Whether it is an eCommerce store, SaaS platform, streaming website, or enterprise application, downtime can lead to revenue loss, poor customer experience, and damaged reputation. This is why businesses are increasingly investing in dedicated server load balancing and high availability setups to ensure maximum uptime and performance.
A single server may work well for smaller workloads, but as traffic grows and applications become more critical, relying on one machine creates a major risk. Hardware failures, unexpected traffic spikes, software crashes, and network interruptions can all impact service availability. A properly designed high availability infrastructure helps eliminate these risks while improving scalability and stability.
In this guide, we will explore how load balancing servers work, why high availability matters, and how businesses can build a reliable server infrastructure for modern applications.
Understanding Dedicated Server Load Balancing
Dedicated server load balancing is the process of distributing incoming traffic across multiple servers instead of relying on a single machine. The main goal is to prevent overload on one server and ensure applications continue running smoothly even during heavy traffic conditions.
A load balancer acts as the traffic controller between users and backend servers. Instead of visitors directly connecting to a single server, requests are routed through the load balancer, which intelligently distributes traffic based on server health, capacity, and availability.
This setup provides several benefits:
- Better website and application performance
- Improved scalability for growing traffic
- Reduced server overload risks
- Higher uptime and reliability
- Improved user experience during peak usage
- Enhanced fault tolerance
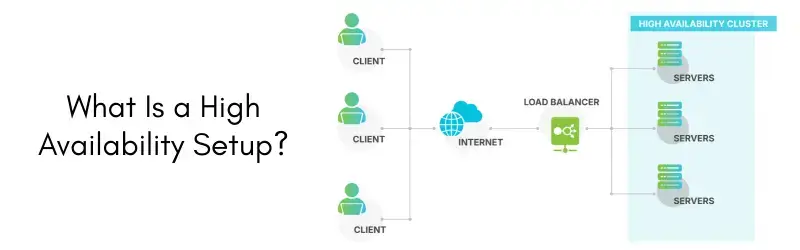
What Is a High Availability Setup?
A high availability setup refers to an infrastructure design focused on minimizing downtime and eliminating single points of failure. The objective is to ensure services remain available even if one server, network component, or hardware device fails.
In a dedicated server high availability environment, multiple servers operate together to provide redundancy. If one system experiences issues, traffic is automatically redirected to healthy servers without interrupting users.
High availability setups are commonly used for:
- Mission-critical business applications
- Financial platforms
- Enterprise ERP systems
- Web hosting environments
- Streaming platforms
- Gaming infrastructure
- Large eCommerce stores
- Database clusters
The combination of server redundancy and intelligent traffic distribution creates a resilient infrastructure capable of handling failures gracefully.
Core Components of a High Availability Infrastructure
Building an HA infrastructure involves several important components working together.
1. Load Balancer
The load balancer is the heart of the traffic distribution system. It monitors backend servers and directs incoming requests accordingly.
Popular load balancing technologies include:
- HAProxy
- NGINX
- Traefik
- F5 Load Balancers
- Citrix ADC
Load balancers can distribute traffic using various methods:
- Round Robin
- Least Connections
- IP Hash
- Weighted Distribution
- Geographic Routing
The right method depends on application behavior and workload patterns.
2. Multiple Dedicated Servers
Instead of one server handling all requests, multiple dedicated servers work together as a cluster. These servers can either actively process traffic simultaneously or remain in standby mode for failover protection.
This redundancy significantly improves application availability and reliability.
3. Health Monitoring
Continuous monitoring is essential in a failover server setup. Monitoring systems check server health, application status, response time, and network availability.
If a server becomes unavailable, traffic is automatically rerouted to healthy systems.
Monitoring tools commonly used include:
- Prometheus
- Zabbix
- Nagios
- Grafana
- Datadog
4. Shared or Replicated Storage
Many high availability environments use replicated storage systems to ensure data consistency across multiple servers.
Storage replication prevents data loss during failures and ensures applications continue operating with synchronized information.
5. Network Redundancy
Reliable HA infrastructure also requires network redundancy. This includes:
- Multiple uplinks
- Redundant switches
- Backup routing
- DDoS protection
- Redundant firewalls

Benefits of Dedicated Server High Availability
Implementing a dedicated server high availability environment offers several operational and business advantages.
Improved Uptime
High availability systems reduce the risk of unexpected outages by eliminating single points of failure. This helps businesses achieve better service continuity.
Better Performance During Traffic Spikes
Load balancing servers distribute requests evenly across backend systems, preventing bottlenecks and maintaining fast response times.
Scalability
Businesses can easily add additional servers as traffic grows. This horizontal scaling model makes expansion simpler and more cost-effective.
Reduced Risk of Downtime
Hardware failures, software crashes, or maintenance activities no longer result in complete service disruption.
Better User Experience
Visitors experience faster loading times, reduced latency, and uninterrupted service availability.
Maintenance Without Downtime
With proper redundancy, administrators can perform updates and maintenance without taking applications offline.
Common Load Balancing Architectures
Different businesses use different load balancing architectures depending on application requirements.
Active-Active Setup
In an active-active architecture, all servers actively process traffic simultaneously.
Advantages include:
- Better resource utilization
- Improved scalability
- Faster traffic handling
- Increased redundancy
This setup is ideal for high-traffic applications and enterprise environments.
Active-Passive Setup
In this configuration, one server actively handles traffic while the backup server remains on standby.
If the primary server fails, the passive server automatically takes over.
This setup is commonly used for:
- Critical business applications
- Database failover systems
- Disaster recovery environments
Geographic Load Balancing
Global applications often use geographic routing to direct users to the nearest data center.
Benefits include:
- Lower latency
- Faster page loading
- Better regional availability
- Improved disaster resilience
Best Practices for High Availability Setup
A successful high availability setup requires careful planning and proper implementation.
Eliminate Single Points of Failure
Every critical component should have redundancy. This includes:
- Power supplies
- Network connections
- Firewalls
- Storage systems
- Load balancers
- Database servers
Use Reliable Monitoring
Real-time monitoring helps detect issues before they become major outages.
Businesses should monitor:
- CPU usage
- RAM utilization
- Disk performance
- Application response times
- Network latency
- SSL certificate status
Implement Automatic Failover
Automatic failover mechanisms reduce downtime by instantly rerouting traffic when problems occur.
Keep Backups Separate
Backups should be stored independently from the main infrastructure.
Using remote backup locations or object storage improves disaster recovery capabilities.
Regularly Test Failover Scenarios
Many organizations build HA systems but never properly test them.
Regular failover testing ensures:
- Backup systems work correctly
- Traffic rerouting functions properly
- Recovery procedures are validated
- Staff understand emergency response steps
Secure the Infrastructure
Security is essential in enterprise server uptime planning.
Recommended practices include:
- DDoS protection
- Firewall hardening
- Access control policies
- VPN-based administration
- Intrusion detection systems
- Regular patch management
Load Balancing for Different Use Cases
eCommerce Websites
Online stores often experience traffic spikes during sales events and promotions.
Load balancing ensures shopping carts, payment gateways, and product pages remain responsive during high demand.
SaaS Platforms
SaaS applications require continuous availability because customers depend on them daily.
High availability architecture helps maintain uninterrupted service delivery.
Gaming Servers
Gaming platforms need low latency and stable performance.
Load balancing helps distribute player sessions efficiently.
Streaming Platforms
Video streaming services handle large bandwidth consumption.
Distributed server infrastructure helps optimize content delivery and playback performance.
Enterprise Applications
ERP systems, CRMs, and internal business applications require reliable uptime to maintain productivity.
HA infrastructure helps organizations avoid costly disruptions.
Choosing the Right Data Center Environment
The quality of the data center environment directly impacts dedicated hosting infrastructure reliability.
Businesses should evaluate:
- Power redundancy
- Cooling systems
- Network carriers
- Security standards
- DDoS mitigation
- Geographic location
- SLA guarantees
- Hardware quality

Future Trends in High Availability Infrastructure
Modern high availability infrastructure is evolving rapidly.
Some major trends include:
AI-Powered Traffic Optimization
Artificial intelligence is increasingly being used to predict traffic patterns and optimize server allocation dynamically.
Container-Based Load Balancing
Container orchestration platforms such as Kubernetes simplify application scaling and redundancy.
Hybrid Cloud Redundancy
Businesses are combining dedicated servers with cloud infrastructure for greater flexibility and disaster recovery.
Edge Computing Integration
Edge computing helps reduce latency by processing traffic closer to users.
This improves application performance for global audiences.
Conclusion
Dedicated server load balancing and high availability setups are essential for businesses that require stable, scalable, and reliable online infrastructure. As traffic demands increase and customer expectations continue to grow, relying on a single server becomes a major operational risk.
A properly designed high availability setup improves uptime, distributes traffic efficiently, reduces downtime risks, and enhances overall application performance. Whether for eCommerce, SaaS platforms, enterprise applications, or streaming services, load balancing servers help create a resilient infrastructure capable of handling modern digital workloads.
By implementing server redundancy, intelligent traffic distribution, monitoring systems, and failover mechanisms, businesses can maintain reliable operations while preparing for future growth.
Organizations investing in dedicated server high availability today are better positioned to deliver uninterrupted digital experiences and maintain long-term operational stability.

